- ELK
- Data Science
- ELASTICSEARCH Install on ubuntu
- ELASTICSEARCH Basic Concepts
- ELASTICSEARCH CRUD
- ELASTICSEARCH Update
- ELASTICSEARCH Bulk
- ELASTICSEARCH Mapping
- ELASTICSEARCH Search
- ELASTICSEARCH Aggregation(Metric)
- ELASTICSEARCH Aggregation(Bucket)
- KIBANA Install on ubuntu
- KIBANA Management
- KIBANA Discover
- KIBANA Visualize 1
- KIBANA Visualize 2
- KIBANA Dashboard
- LOGSTASH Install on ubuntu
- Practical data analysis using ELK 1 - Population
- Practical data analysis using ELK 2 - Stock
ELK
Data Science
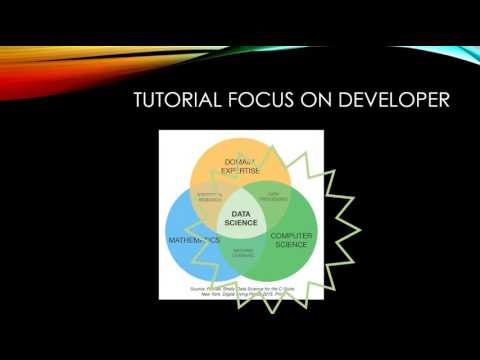
ELK Stack

ELASTICSEARCH
https://www.elastic.co/kr/products/elasticsearch
Lucene 기반 검색 엔진 HTTP 웹 인터페이스와 JSON 문서 객체를 이용해 분산된 multitenant 가능한 검색을 지원한다.
LOGSTASH
https://www.elastic.co/kr/products/logstash
server-side 처리 파이프라인, 다양한 소스에서 동시에 Data를 수집-변환 후 Stash로 전송
KIBANA
https://www.elastic.co/kr/products/kibana
ELASTICSEARCH data를 시각화하고 탐색을 지원
ELASTICSEARCH Install on ubuntu

Install JAVA 8
sudo add-apt-repository -y ppa:webupd8team/java
sudo apt-get update
sudo apt-get -y install oracle-java8-installer
java -version
Install ELASTICSEARCH
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.1.deb
dpkg -i elasticsearch-5.3.1.deb
sudo systemctl enable elasticsearch.service
- Install path: /usr/share/elasticsearch
- Config file: /etc/elasticsearch
- Init script: /etc/init.d/elasticsearch
ELASTICSEARCH Start | Stop | Check
sudo service elasticsearch start
sudo service elasticsearch stop
curl -XGET 'localhost:9200' # check run
ELASTICSEARCH config (External network)
Allow All Host (AWS 같은 클라우드 서비스를 사용하는 경우 외부에서 접속하기 때문에 네트워크 설정 필요)
vi /etc/elasticsearch/elasticsearch.yml
network.host: 0.0.0.0
이런 경우 앞으로 사용될 localhost를 각자의 IP로 변경한다.
locahlost:9200 -> 119.10.10.10:9200
ELASTICSEARCH Basic Concepts

ELASTICSEARCH vs RDB
| ELASTICSEARCH | RDB |
|---|---|
| Index | Database |
| Type | Table |
| Document | Row |
| Field | Column |
| Mapping | Schema |
http://d2.naver.com/helloworld/273788
| RDB | ELASTICSEARCH |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| Index | Everything is indexed |
| SQL | Query |
ELASTICSEARCH CRUD

ELASTICSEARCH에 Document(Row)를 삽입, 삭제, 조회
| ELASTICSEARCH | RDB | CRUD |
|---|---|---|
| GET | SELECT | READ |
| PUT | UPDATE | UPDATE |
| POST | INSERT | CREATE |
| DELETE | DELETE | DELETE |
Verify Index
curl -XGET localhost:9200/classes
curl -XGET localhost:9200/classes?pretty
?pretty: JSON fotmatting
Create Index
curl -XPUT localhost:9200/classes
Success: {"acknowledged":true,"shards_acknowledged":true}
Delete Index
curl -XDELETE localhost:9200/classes
Success: {"acknowledged":true}
Create Document
curl -XPOST localhost:9200/classes/class/1/ -d '{"title":"A", "professor":"J"}'
Success: {"_index":"classes","_type":"class","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"created":true}
Create Document from File
curl -XPOST localhost:9200/classes/class/1/ -d @oneclass.json
Fail: {"error":{"root_cause":[{"type":"null_pointer_exception","reason":null}],"type":"null_pointer_exception","reason":null},"status":500}Success: {"_index":"classes","_type":"class","_id":"1","_version":2,"result":"updated","_shards":{"total":2,"successful":1,"failed":0},"created":false}
oneclass.json
{
"title" : "Machine Learning",
"Professor" : "Minsuk Heo",
"major" : "Computer Science",
"semester" : ["spring", "fall"],
"student_count" : 100,
"unit" : 3,
"rating" : 5
}
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch01/oneclass.json
ELASTICSEARCH Update
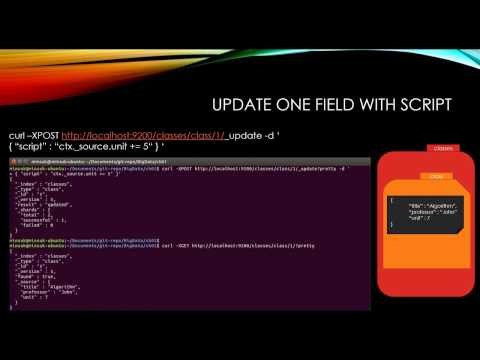
ELASTICSEARCH에 Document(Row)를 수정
curl -XPOST localhost:9200/classes/class/1/ -d '{"title":"Algorithm", "professor":"John"}'
classes: Index ( RDB's Database )class: Type ( RDB's Table )1: Document ( RDB's Row )
Add Field
RDB's Column
Way 1. Basic
curl -XPOST localhost:9200/classes/class/1/_update -d '{"doc":{"unit":1}}'
curl -XGET localhost:9200/classes/class/1?pretty
| Before | After |
|---|---|
| {"title":"Algorithm", "professor":"John"} | {"title":"Algorithm", "professor":"John", "unit": 1} |
Way 2. Script
curl -XPOST localhost:9200/classes/class/1/_update -d '{"script":"ctx._source.unit +=5"}'
ELASTICSEARCH Bulk

File로 된 여러 개의 Documents를 한 번에 저장
curl -XPOST localhost:9200/_bulk?pretty --data-binary @classes.json
Get classes.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch02/classes.json#
ELASTICSEARCH Mapping

RDB's Schema. 효율적인 검색을 위해서 데이터의 타입을 정의하는 것
Step 1. Create Index
curl -XPUT localhost:9200/classes
Error
{
"error": {
"root_cause": [
{
"type": "index_already_exists_exception",
"reason": "index [classes/5mBFGPEwRpOdJP08VNDJug] already exists",
"index_uuid": "5mBFGPEwRpOdJP08VNDJug",
"index": "classes"
}
],
"type": "index_already_exists_exception",
"reason": "index [classes/5mBFGPEwRpOdJP08VNDJug] already exists",
"index_uuid": "5mBFGPEwRpOdJP08VNDJug",
"index": "classes"
},
"status": 400
}
curl -XDELETE localhost:9200/classes
curl -XPUT localhost:9200/classes
Success
{
"classes" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1493388598544",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "N2GHTYgFQqOy_DoP9zuISA",
"version" : {
"created" : "5030199"
},
"provided_name" : "classes"
}
}
}
}
Mapping 없이 Index만 생성했기 때문에,
classes.mappings의 값이 빈 객체이다.
Step 2. Create Mapping
2-1 Get classesRating_mapping.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch02/classesRating_mapping.json
2-2 Mapping
curl -XPUT localhost:9200/classes/class/_mapping -d @classesRating_mapping.json
2-3 Verify Mapping
curl -XGET localhost:9200/classes?pretty
Success
{
"classes" : {
"aliases" : { },
"mappings" : {
"class" : {
"properties" : {
"major" : {
"type" : "text"
},
"professor" : {
"type" : "text"
},
"rating" : {
"type" : "integer"
},
"school_location" : {
"type" : "geo_point"
},
"semester" : {
"type" : "text"
},
"student_count" : {
"type" : "integer"
},
"submit_date" : {
"type" : "date",
"format" : "yyyy-MM-dd"
},
"title" : {
"type" : "text"
},
"unit" : {
"type" : "integer"
}
}
}
},
"settings" : {
"index" : {
"creation_date" : "1493388598544",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "N2GHTYgFQqOy_DoP9zuISA",
"version" : {
"created" : "5030199"
},
"provided_name" : "classes"
}
}
}
}
2-4 Add Documents
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch02/classes.json
curl -XPOST localhost:9200/_bulk?pretty --data-binary @classes.json
Verify Documents
curl -XGET localhost:9200/classes/class/1?pretty
ELASTICSEARCH Search

Get simple_basketball.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/simple_basketball.json#
Add Documents
curl -XPOST localhost:9200/_bulk --data-binary @simple_basketball.json
Search
Search - Basic
curl -XGET localhost:9200/basketball/record/_search?pretty
Success
{
"took" : 254,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 1.0,
"hits" : [
{
"_index" : "basketball",
"_type" : "record",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"team" : "Chicago Bulls",
"name" : "Michael Jordan",
"points" : 20,
"rebounds" : 5,
"assists" : 8,
"submit_date" : "1996-10-11"
}
},
{
"_index" : "basketball",
"_type" : "record",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"team" : "Chicago Bulls",
"name" : "Michael Jordan",
"points" : 30,
"rebounds" : 3,
"assists" : 4,
"submit_date" : "1996-10-11"
}
}
]
}
}
Search - Uri
curl XGET localhost:9200/basketball/record/_search?q=points:30&pretty
Success
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1.0,
"hits": [
{
"_index": "basketball",
"_type": "record",
"_id": "1",
"_score": 1.0,
"_source": {
"team": "Chicago Bulls",
"name": "Michael Jordan",
"points": 30,
"rebounds": 3,
"assists": 4,
"submit_date": "1996-10-11"
}
}
]
}
}
Search - Request body
curl XGET localhost:9200/basketball/record/_search -d '{"query":{"term":{"points":30}}}'
curl XGET localhost:9200/basketball/record/_search -d '{
"query": {
"term": {
"points": 30
}
}
}'
ELASTICSEARCH Aggregation(Metric)

평균, 합, 최소, 최대 등 산술 분석을 제공
Add Documents
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/simple_basketball.json
curl -XPOST localhost:9200/_bulk --data-binary @simple_basketball.json
Average
curl -XGET localhost:9200/_search?pretty --data-binary @avg_points_aggs.json
Get avg_points_aggs.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/avg_points_aggs.json
{
"size": 0,
"aggs": {
"avg_score": {
"avg": {
"field": "points"
}
}
}
}
Max
curl -XGET localhost:9200/_search?pretty --data-binary @max_points_aggs.json
Get max_points_aggs.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/max_points_aggs.json
{
"size": 0,
"aggs": {
"max_score": {
"max": {
"field": "points"
}
}
}
}
Min
curl -XGET localhost:9200/_search?pretty --data-binary @min_points_aggs.json
Get min_points_aggs.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/min_points_aggs.json
{
"size": 0,
"aggs": {
"min_score": {
"min": {
"field": "points"
}
}
}
}
Sum
curl -XGET localhost:9200/_search?pretty --data-binary @sum_points_aggs.json
Get sum_points_aggs.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/sum_points_aggs.json
{
"size": 0,
"aggs": {
"sum_score": {
"sum": {
"field": "points"
}
}
}
}
Stats
평균, 합, 최소, 최대 한 번에 도출
curl -XGET localhost:9200/_search?pretty --data-binary @stats_points_aggs.json
Get stats_points_aggs.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch03/stats_points_aggs.json
{
"size": 0,
"aggs": {
"stats_score": {
"stats": {
"field": "points"
}
}
}
}
ELASTICSEARCH Aggregation(Bucket)
RDB's
Group by. 데이터를 일정 기준으로 묶어서 결과를 도출.
Create Basketball Index
curl -XPUT localhost:9200/basketball
Mapping Basketball
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch04/basketball_mapping.json
curl -XPUT localhost:9200/basketball/record/_mapping -d @basketball_mapping.json
Add Basketball Documents
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch04/twoteam_basketball.json
curl -XPOST localhost:9200/_bulk --data-binary @twoteam_basketball.json
Term Aggs - Group by(team)
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch04/terms_aggs.json
curl -XGET localhost:9200/_search?pretty --data-binary @terms_aggs.json
Stats Aggs - Group by(team)
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch04/stats_by_team.json
curl -XGET localhost:9200/_search?pretty --data-binary @stats_by_team.json
KIBANA Install on ubuntu

Install KIBANA
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.3.1-amd64.deb
dpkg -i kibana-5.3.1.deb
Config
vi /etc/kibana/kibana.yml
#server.host: "localhost"
#elasticsearch.url: "http://localhost:9200"
Network
AWS 같은 클라우드 서비스를 사용하는 경우 localhost가 아닌 내부 IP 설정
ifconfig | grep inet
It will returns
inet addr:192.169.212.10 Bcast:192.169.212.255 Mask:255.255.255.0 inet6 addr: fe80::d00d:d9ff:fecc:9dfd/64 Scope:Link inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host
server.host: 192.169.212.10
Start KIBANA
sudo /usr/share/kibana/bin/kibana
KIBANA Management

ELASTICSEARCH 저장된 데이터 중 어떤 Index( RDB's Database )를 시각화할지 정한다.
Step 1. Set Basketball Data
curl -XDELETE localhost:9200/basketball
curl -XPUT localhost:9200/basketball
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch04/basketball_mapping.json
curl -XPUT localhost:9200/basketball/record/_mappin -d @basketball_mapping.json
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch05/bulk_basketball.json
curl -XPOST localhost:9200/_bulk --data-binary @bulk_basketball.json
Step 2. Access KIBANA
AWS 같은 클라우드를 사용하면
localhost를 각자의 IP 주소로 바꾼다.
Go To Management Tab (http://localhost:5601/app/kibana#/management/kibana/index?_g=())
Create Index Patterns
- Index name or pattern
- basketball*
- Time-field name
- submit_date

Created

KIBANA Discover

ELASTICSEARCH 의 저장된 데이터를 JSON, Table 형식으로 보여준다. Filter를 이용해서 원하는 정보만 볼 수 있다.
Go To Discover Tab (http://localhost:5601/app/kibana#/discover)
Step 1. Time Range

Step 2. Select Item

Step 3. Filtering

Step 4. Toggle

KIBANA Visualize 1

막대 차트와 파이 차트로 데이터 시각화를 실습한다.
Go To Visualize Tab (http://localhost:5601/app/kibana#/visualize)
Vertical bar chart
metrics
- Y-Axis
- Aggregation
- Average
- Field
- points
- Custom Label
- avg
- Aggregation
buckets
- X-Axis
- Aggregation
- Terms
- Field
- name.keyword
- Order by
- metric: avg
- Aggregation

Result

Pie bar chart
metrics
- Slice Size
- Aggregation
- Sum
- Field
- points
- Aggregation
buckets
- Split Slices
- Aggregation
- Terms
- Field
- team.keyword
- Order by
- metric: Sum of points
- Aggregation

Result

KIBANA Visualize 2

Map 차트를 이용한 데이터 시각화를 실습한다.
Create Mapping
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch02/classesRating_mapping.json
curl -XPUT localhost:9200/classes/class/_mapping -d @classesRating_mapping.json
Add Documents
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch02/classes.json#
curl -XPUT localhost:9200/_bulk?pretty --data-binary @classes.json
Verify Documents
curl -XGET localhost:9200/classes/class/1?pretty
Kibana Management
- Index name or pattern
- classes*
- Time-field name
- submit_date

Kibana Visualize - Tile map
buckets
- Geo Coordinates
- Aggregation
- Geohash
- Field
- school_location
- Aggregation

KIBANA Dashboard

Kibana Visualize
Vertical bar chart -> classes
metrics
- Y-Axis
- Aggregation
- Average
- Field
- points
- Aggregation
buckets
- X-Axis
- Aggregation
- Terms
- Field
- Professor.keyword
- Order
- Descending
- Size
- 16
- Aggregation

Result

Save

Create Dashboard
Go To Dashboard Tab (http://localhost:5601/app/kibana#/dashboards)
Create a dashboard -> Add -> Select Dashboard -> Save

LOGSTASH Install on ubuntu
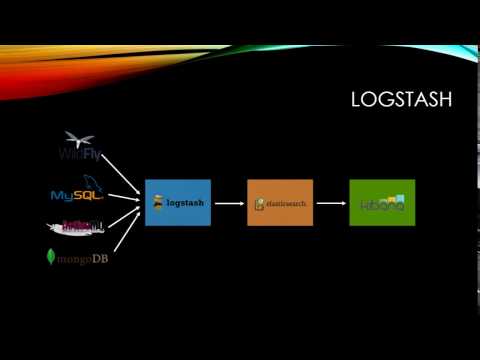
LOGSTASH는
ELK스택에서 Input에 해당한다. 다양한 형태의 데이터를 받아들여서 사용자가 지정한 형식에 맞게 필터링한 후 ELASTICSEARCH로 보낸다.
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to your favorite “stash.”
Install LOGSTASH
Java must required first!!
wget https://artifacts.elastic.co/downloads/logstash/logstash-5.3.1.deb
dpkg -i logstash-5.3.1.deb
- Install path: /usr/share/logstash
Config LOGSTASH
vi logstash-simple.conf
input {
stdin { }
}
output {
stdout { }
}
Run LOGSTASH
sudo /usr/share/logstash/bin/logstash -f ./logstash-simple.conf
Practical data analysis using ELK 1 - Population

현재까지 구성된
ELK스택을 이용해서 세계 인구 분석을 실습한다.
Collect Datas
Datas site
https://catalog.data.gov/dataset
Population analysis Datas
https://catalog.data.gov/dataset/population-by-country-1980-2010-d0250
Get Ready-to-use Datas
Site에서 받은 데이터는 약간의 수정이 필요하다. 아래의 데이터는 바로 사용할 수 있는 데이터.
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch06/populationbycountry19802010millions.csv
Check ELASTICSEARCH & KIBANA are running
Check KIBANA
ps -ef | grep kibana
Running
root 29968 29933 9 16:58 pts/0 00:00:06 /usr/share/kibana/bin/../node/bin/node --no-warnings /usr/share/kibana/bin/../src/cli
root 30036 30018 0 16:59 pts/1 00:00:00 grep --color=auto kibana
Stopped
root 29957 29933 0 16:57 pts/0 00:00:00 grep --color=auto kibana
Restart
sudo /usr/share/kibana/bin/kibana
Check ELASTICSEARCH
service elasticsearch status
## OR
curl -XGET 'localhost:9200'
Running
● elasticsearch.service - Elasticsearch ....
## OR
{
"name" : "lPQjk0j",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "MORDslcmSKywLz4ReZtsIA",
"version" : {
"number" : "5.3.1",
"build_hash" : "5f9cf58",
"build_date" : "2017-04-17T15:52:53.846Z",
"build_snapshot" : false,
"lucene_version" : "6.4.2"
},
"tagline" : "You Know, for Search"
}
Stopped
curl: (7) Failed to connect to localhost port 9200: Connection refused
Restart
sudo service elasticsearch start
Config LOGSTASH
받은 파일을 LOGSTASH를 이용해서 필터링한 후 ELASTICSEARCH에 넣어준다.
vi logstash.conf
input {
file {
path => "/home/minsuk/Documents/git-repo/BigData/ch06/populationbycountry19802010millions.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["Country","1980","1981","1982","1983","1984","1985","1986","1987","1988","1989","1990","1991","1992","1993","1994","1995","1996","1997","1998","1999","2000","2001","2002","2003","2004","2005","2006","2007","2008","2009","2010"]
}
mutate {convert => ["1980", "float"]}
mutate {convert => ["1981", "float"]}
mutate {convert => ["1982", "float"]}
mutate {convert => ["1983", "float"]}
mutate {convert => ["1984", "float"]}
mutate {convert => ["1985", "float"]}
mutate {convert => ["1986", "float"]}
mutate {convert => ["1987", "float"]}
mutate {convert => ["1988", "float"]}
mutate {convert => ["1989", "float"]}
mutate {convert => ["1990", "float"]}
mutate {convert => ["1991", "float"]}
mutate {convert => ["1992", "float"]}
mutate {convert => ["1993", "float"]}
mutate {convert => ["1994", "float"]}
mutate {convert => ["1995", "float"]}
mutate {convert => ["1996", "float"]}
mutate {convert => ["1997", "float"]}
mutate {convert => ["1998", "float"]}
mutate {convert => ["1999", "float"]}
mutate {convert => ["2000", "float"]}
mutate {convert => ["2001", "float"]}
mutate {convert => ["2002", "float"]}
mutate {convert => ["2003", "float"]}
mutate {convert => ["2004", "float"]}
mutate {convert => ["2005", "float"]}
mutate {convert => ["2006", "float"]}
mutate {convert => ["2007", "float"]}
mutate {convert => ["2008", "float"]}
mutate {convert => ["2009", "float"]}
mutate {convert => ["2010", "float"]}
}
output {
elasticsearch {
hosts => "localhost"
index => "population"
}
stdout {}
}
- input -> file -> path
- Edit
Yourown file path - e.g.) "/root/populationbycountry19802010millions.csv"
- Edit
OR Download logstash.conf file
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch06/logstash.conf
Run LOGSTASH output to ELASTICSEARCH
/usr/share/logstash/bin/logstash -f ./logstash.conf
Go KIBANA
http://localhost:5601/app/kibana#/management?_g=()
Add pattern

Discover Tab

Visualize Tab
Practical data analysis using ELK 2 - Stock

현재까지 구성된
ELK스택을 이용해서 주식 분석을 실습한다.
http://blog.webkid.io/visualize-datasets-with-elk/
Collcet Datas
Datas site
Stock analysis Datas - Facebook
Get Ready-to-use Datas
Site에서 받은 데이터는 약간의 수정이 필요하다. 아래의 데이터는 바로 사용할 수 있는 데이터.
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch06/table.csv
Check ELASTICSEARCH & KIBANA are running
Check ELASTICSEARCH
service elasticsearch status
Check KIBANA
ps -ef | grep kibana
Config LOGSTASH
vi logstash_stock.conf
input {
file {
path => "/home/minsuk/Documents/git-repo/BigData/ch06/table.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["Date","Open","High","Low","Close","Volume","Adj Close"]
}
mutate {convert => ["Open", "float"]}
mutate {convert => ["High", "float"]}
mutate {convert => ["Low", "float"]}
mutate {convert => ["Close", "float"]}
}
output {
elasticsearch {
hosts => "localhost"
index => "stock"
}
stdout {}
}
- input -> file -> path
- Edit
Yourown file path - e.g.) "/root/table.csv"
- Edit
OR Download logstash_stock.conf file
wget https://raw.githubusercontent.com/minsuk-heo/BigData/master/ch06/logstash_stock.conf
Run LOGSTASH output to ELASTICSEARCH
/usr/share/logstash/bin/logstash -f ./logstash_stock.conf
Go KIBANA
http://localhost:5601/app/kibana#/management?_g=()
Add pattern

Visualize Tab
Line chart

Result

Dashboard Tab
